
The AI art scene is getting hotter. Sana, a new AI model introduced by Nvidia, runs high-quality 4K image generation on consumer-grade hardware, thanks to a clever mix of techniques that differ a bit from the way traditional image generators work.
Sana’s speed comes from what Nvidia calls a “deep compression autoencoder” that squeezes image data down to 1/32nd of its original size—while keeping all the details intact. The model pairs this with the Gemma 2 LLM to understand prompts, creating a system that punches well above its weight class on modest hardware.
If the final product is as good as the public demo, Sana promises to be a brand new image generator built to run on less demanding systems, which will be a huge advantage for Nvidia as it tries to reach even more users.
“Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput,” the team at Nvidia wrote on Sana’s research paper, “Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image.”
Yes, you read that right: Sana is a 0.6 Billion parameter model that competes against models 20 times its size, while generating images 4 times larger, in a fraction of the time. If that sounds too good to be true, you can try it yourself on a special interface set up by the MIT.
Nvidia’s timing couldn’t be more pointed, with models like the recently introduced Stable Diffusion 3.5, the beloved Flux, and the new Auraflow already battling for attention. Nvidia plans to release its code as open source soon, a move that could solidify its position in the AI art world—while boosting sales of its GPUs and software tools, shall we add.
The Holy Trinity that make Sana so good
Sana is basically a reimagination of the way traditional image generators work. But there are three key elements that make this model so efficient.
First, is Sana’s deep compression autoencoder, which shrinks image data to a mere 3% of its original size. The researchers say, this compression uses a specialized technique that maintains intricate details while dramatically reducing the processing power needed.
You can think of this as an optimized substitute to the Variable Auto Encoder that’s implemented in Flux or Stable Diffusion. The encode/decode process in Sana is built to be faster and more efficient.
These auto encoders basically translate the latent representations (what the AI understands and generates) into images.
Secondly, Nvidia overhauled the way its model deals with prompts—which is by encoding and decoding text. Most AI art tools use text encoders like T5 or CLIP to basically translate the user’s prompt into something an AI can understand—latent representations from text. But Nvidia chose to use Google’s Gemma 2 LLM.
This model does basically the same thing, but stays light while still catching nuances in user prompts. Type in “sunset over misty mountains with ancient ruins,” and it gets the picture—literally—without maxing out your computer’s memory.
But the Linear Diffusion Transformer is probably the main departure from traditional models. While other AI tools use complex mathematical operations that bog down processing, Sana’s LDT strips away unnecessary calculations. The result? Lightning-fast image generation without quality loss. Think of it as finding a shortcut through a maze—same destination, but a much faster route.
This could be an alternative to the UNet architecture that AI artists know from models like Flux or Stable Diffusion. The UNet is what transforms noise (something that makes no sense) into a clear image by applying noise-removal techniques, gradually refining the image through several steps—the most resource-hungry process in image generators.
So, the LDT in Sana essentially performs the same “de-noising” and transformation tasks as the UNet in Stable Diffusion but with a more streamlined approach. This makes LDT a crucial factor in achieving high efficiency and speed in Sana’s image generation, while UNet remains central to Stable Diffusion’s functionality, albeit with higher computational demands.
Basic Tests
Since the model isn’t publicly released, we won’t share a detailed review. But some of the results we obtained from the model’s demo site were quite good.
Sana proved to be quite fast. For comparison, it was able to generate 4K images, rendering 30 steps in less than 10 seconds. That is even faster than the time it takes Flux Schnell to generate a similar image in 4 steps with 1080p sizes.
Here are some results, using the same prompts we used to benchmark other image generators:
Prompt 1: “Hand-drawn illustration of a giant spider chasing a woman in the jungle, extremely scary, anguish, dark and creepy scenery, horror, hints of analog photography influence, sketch.”


Prompt 2: A black and white photo of a woman with long straight hair, wearing an all-black outfit that accentuates her curves, sitting on the floor in front of a modern sofa. She is posing confidently for the camera, showcasing her slender legs as she crouches down. The background features a minimalist design, emphasizing her elegant pose against the stark contrast between light gray walls and dark attire. Her expression exudes confidence and sophistication. Shot by Peter Lindbergh using Hasselblad X2D 105mm lens at f/4 aperture setting. ISO 63. Professional color grading enhances the visual appeal.


Prompt 3: A Lizard Wearing a Suit


Prompt 4: A beautiful woman lying on grass


Prompt 5: “A dog standing on top of a TV showing the word ‘Decrypt’ on the screen. On the left there is a woman in a business suit holding a coin, on the right there is a robot standing on top of a first aid box. The overall scenery is surreal.”


The model is also uncensored, with a proper understanding of both male and female anatomy. It will also make it easier to fine tune once it is released. But considering the important amount of architectural changes, it remains to be seen how much of a challenge it will be for model developers to understand its intricacies and release custom versions of Sana.
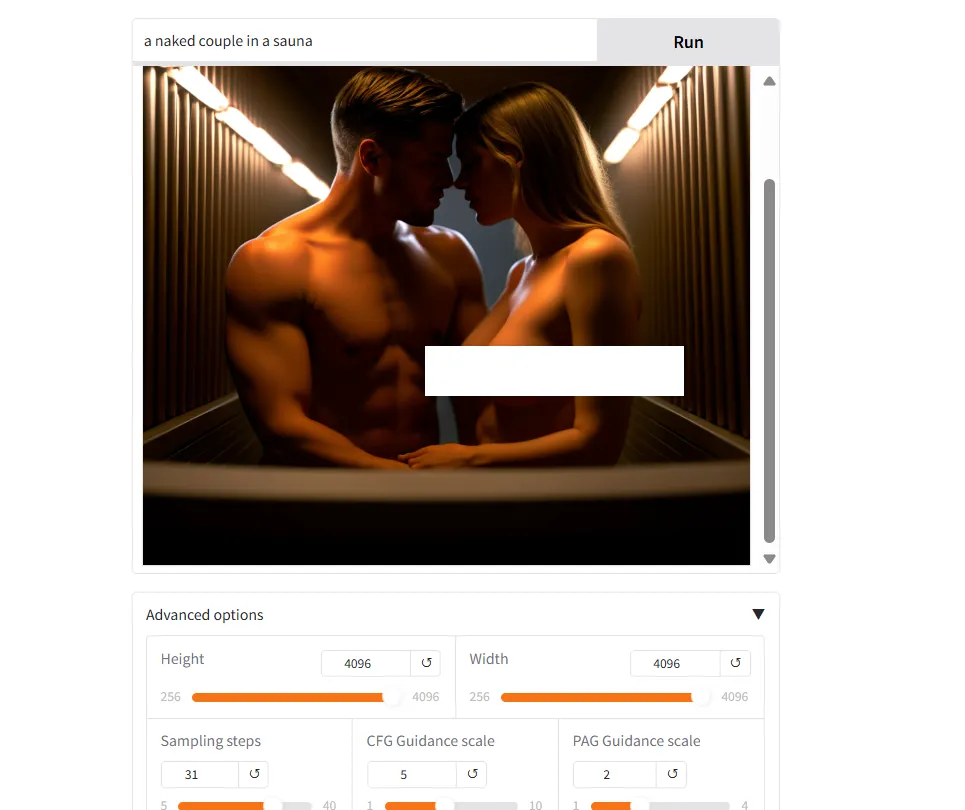
Based on these early results, the base model, still in preview, seems good with realism while bein versatile enough for other types of art. It is good in terms of space awareness but its main flaw is its lack of proper text generation and lack of detail under some conditions.
The speed claims are quite impressive, and the ability to generate 4096×4096—which is technically higher than 4k—is something remarkable, considering that such sizes can only be properly achieved today with upscaling techniques.
The fact that it will be open source is also a major positive, so we may soon be reviewing models and finetunes capable of generating ultra high definition images without putting too much pressure on consumer hardware.
Sana’s weights will be released on the project’s official Github.